title: 理解UTF编码 date: 2023-01-10 categories: - ProgrammingTool tags: - UTF编码 description: 理解Unicode编码的各种概念
Introduction
ASCII码
在计算机中,所有数据最终都是一个二进制值。对于符号类型的数据(例如:a,b,c),我们就需要把它们映射为指定的二进制表示(这就叫做编码)。上世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为ASCII码,一直沿用至今。
ASCII码使用指定的7 位或8 位二进制数组合来表示128 或256 种可能的字符。标准ASCII码使用7位来编码来表示128个字符,剩下的最前面的统一规定为0,例如空格键(space)的二进制表示为0010 0000,十进制数值为10,十六进制表示为0x20
非ASCII码
ASCII码能够表示的字符数量有限,对于英语来说是足够了,但是拓展到其他语言是,这种编码方式是远远不够的。那我们汉字来说,总量的汉字大约有10w个,常用的也有3000。那么拿一个字节来编码汉字肯定是不够的,就需要用多个字节来进行编码。这里就涉及到了两个问题,一个是怎样每个汉字对应的二进制数是多少,第二个就是对于多个字节的汉字,需要以什么样的编码方式来存储对应的二进制数?这两个问题,是理解字符编码的核心。
Unicode
由于字符编码不同,计算机在不同国家之间的交流变得很困难,经常会出现乱码的问题。因为对于同一个二进制数,在不同的国家,会解析出不同的字符。这时候就需要有统一的规则,Unicode应运而生。
字符集和字符编码
字符(Character)是各种文字和符号的总称;字符集(Character Set)是多个字符的集合。有了字符集,我们就需要把字符映射为计算机能够识别的二进制数,这就是字符编码,这个二进制数值我们一般称之为码点。字符编码(Character Encoding)就是把字符集中的字符编码为指定集合中某一对象(例如:比特模式、自然数序列、8位组或者电脉冲),以便文本在计算机中存储和通过通信网络的传递。不同的字符编码,比如常见的UTF8,UTF32它们对应的字符集都是Unicode字符集,只是编码的实现方式不同。
Unicode 是国际标准字符集,它将世界各种语言的每个字符定义一个唯一的编码,以满足跨语言、跨平台的文本信息转换。Unicode 字符集的编码范围是0x0000 - 0x10FFFF, 可以容纳一百多万个字符。例如:大写字母A的码点是 0x41, 具体字符对应的 Unicode 编码可以查询Unicode字符编码表
UTF-8编码
utf8编码是一种变长编码方式,它使用1到4个字节编码全部Unicode码点。具有较小值的码点(通常该字符的出现频率较高)使用较短的字节进行编码。utf8编码能够向后兼容ASCII编码,所以有效的ASCII编码的文本也一定是有效的utf8编码的文本。
Encoding
utf8使用1到4个字节来编码码点的值。对于码点小于128的字符,可以用一个字节(8位)来表示(首位字节设置位0,剩余7位刚好可以表示128个字符)。对于码点值大于128的,由于编码该码点需要多个字节,那么第一个字节的头部有几个1就表示该字符需要多少个字节,剩下的每个字节的开头以10开头,具体可以对照下图:
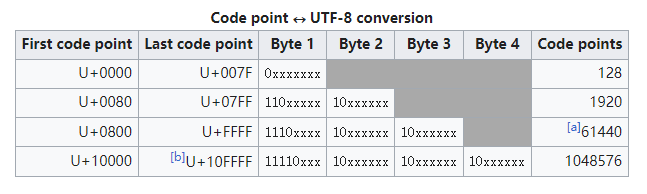
注:这里需要注意下,对于部分复杂的符号,比如emoji表情,它所需的字节可能会大于4个,这是因为它们可以由不同的码点组成。