Introduction
这是一篇关于多模态知识图谱的综述,作者从下面几个方面介绍了目前为止多模态知识图谱的相关工作,多模态知识图谱的构建,多模态任务的相关技术和多模态知识图谱的应用
1. Definition
传统图谱可以看成一个图 \(\mathcal{G} =\{ \mathcal{E},\mathcal{R},\mathcal{A},\mathcal{V},\mathcal{T_{\mathcal{R}}}, \mathcal{T_{\mathcal{A}}} \}\) 其中 \(\mathcal{E}\) 表示实体, \(\mathcal{R}\)表示关系, \(\mathcal{A}\)表示属性, \(\mathcal{V}\) 表示属性值, \(\mathcal{T_{\mathcal{R}}} , \mathcal{T_{\mathcal{A}}}\) 分别表示关系三元组和属性三元组。多模态的知识图谱作为传统知识图谱的一部分,其实就是图谱 \(\{ \mathcal{E},\mathcal{R},\mathcal{A},\mathcal{V},\mathcal{T_{\mathcal{R}}}, \mathcal{T_{\mathcal{A}}} \}\)中知识的多模态化。按照这种思路,多模态图谱的表示大致分为两种:
-
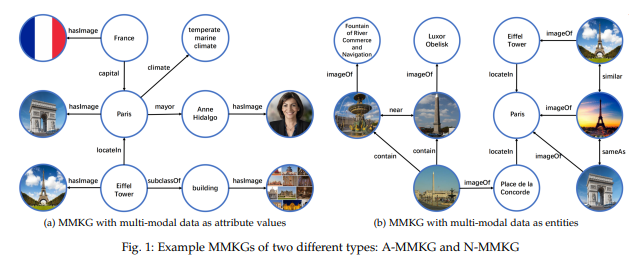
1.A-MMKG
将多模态数据当作实体和概念的特定属性数据,图谱可表示为 \(\mathcal{G} =\{ \mathcal{E},\mathcal{R},\mathcal{A},\mathcal{V},\mathcal{T_{\mathcal{R}}}, \mathcal{T_{\mathcal{A}}} \}\),其中 \(\mathcal{T_{\mathcal{A}}}= \mathcal{E}\times\mathcal{A}\times (\mathcal{V_{\mathcal{KG}}}\cup \mathcal{V_{\mathcal{MM}}})\) -
2.N-MMKG
将多模态数据表示为图谱中的实体,图谱可表示为 \(\mathcal{G} =\{ \mathcal{E},\mathcal{R},\mathcal{A},\mathcal{V},\mathcal{T_{\mathcal{R}}}, \mathcal{T_{\mathcal{A}}} \}\),其中 \(\mathcal{T_{\mathcal{R}}}= (\mathcal{E_{\mathcal{KG}}}\cup \mathcal{E_{\mathcal{MM}}})\times\mathcal{R}\times (\mathcal{E_{\mathcal{KG}}}\cup \mathcal{E_{\mathcal{MM}}})\),显然该表示方案会扩充多模态知识图谱中的光系类型
注:理解属性和关系的区别 关系刻画的是实体与实体之间的联系,属性刻画的是实体本身固有特性
注:图谱如何表示,取决于图谱的本体如何设计和图谱如何应用
具体差异可以参考下图:
2.Construction
多模态图谱构建的本质是构建传统KG中符号化的知识(包括实体、概念和关系)与它们相对应的图像之间的联系。从这个角度出发,图谱构建的方式的出发点就有两个,一个是图像,一个是传统的符号。
从图像到符号-图像打标(Labeling Image)
从已有的图像当中抽取出KG中的符号表示。根据需要链接的符号,可以分成一下主要任务: 主要任务 1. Visual Entity/Concept Extraction 2. Visual Relation Extraction 3. Visual Event Extraction
从符号到图像-符号落地(Symbol Grounding)
- Entity Grounding
Entity Grounding 主要是为实体找到相关的图片。它的难点在于怎么找和怎么匹配。通常的方案是爬取百科类的数据或者利用搜索引擎进行搜索。主要工作都是在做一些数据清洗类
- Concept Grounding
Concept Grounding 主要为概念找到具有代表性的,多样化的,有区分性质的图片。不同于实体,面对概念时,第一,有的概念时不可视的。这里文章举了个例子,叫irreligionist(非宗教主义者) 第二,概念通常时实体的抽象,那么表示概念的图片就会很多,怎么筛选最具代表性的概念就是个问题。例如:Princess(女王)、Physicist(物理学家)。这里 Visualization Concept Judgment是用来探索判别可视化概念, Representative Image Selection 用来筛选具有代表意义的图片 ,Image Diversification用来保证图片能兼具代表性和多样性。
- Relation Grounding
Relation Grounding 主要是寻找能够表示特定关系的图像,给定包含该关系的一个或者多个三元组,能够找到表示该关系的代表性图像。由于关系表示依赖于实体,利用三元组俩检索图像,通常就需要利用Text-Image Matching 技术,Graph Matching技术。