最新的survey可参考:The Elements of Temporal Sentence Grounding in Videos: A Survey and Future Directions
Introduction
Temporal sentence grounding in video(TSGV)任务, 给定一段文本和一段未剪辑的视频,定位到视频中与文本描述相关的目标片段, 一般是识别出目标片段在视频中的开始和结束位置.与 temporal action localization(TAGV)任务不同,TSGV更有灵活性和挑战性。因为它需要理解更复杂的自然语言语义和更复杂的动作类型(一般temporal action localization 会预先定义出动作类别),还需要进行不同模态之间的交互和理解(文本和视频)。具体任务理解可以参考下图:

Background
背景知识主要包含以下几块知识:
- Preprocessor(预处理)
- Feature Extractor(特征抽取)
- Feature Encode and Feature Interactor(特征编码和特征交互)
特征抽取常用方案:基于三维卷积网络的预训练模型C3D或者I3D(Inflated 3D ConvNet); 基于二维卷积网络的预训练模型VGG或者ResNet
Method Overview
根据现有的方案,解决此类问题的范式可以大概分为以下几种:
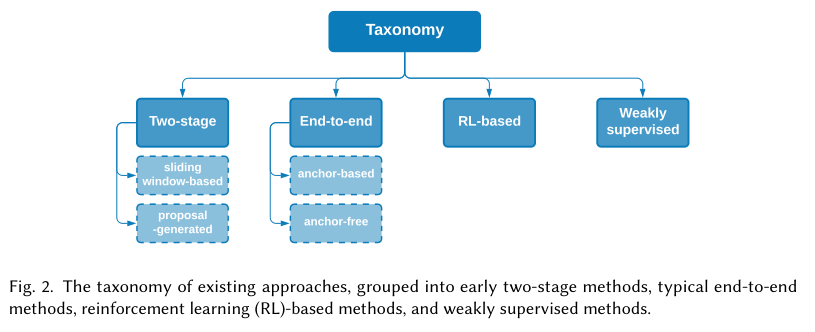
## Two-stage method