具体细节可参考swin transformer
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Introduction
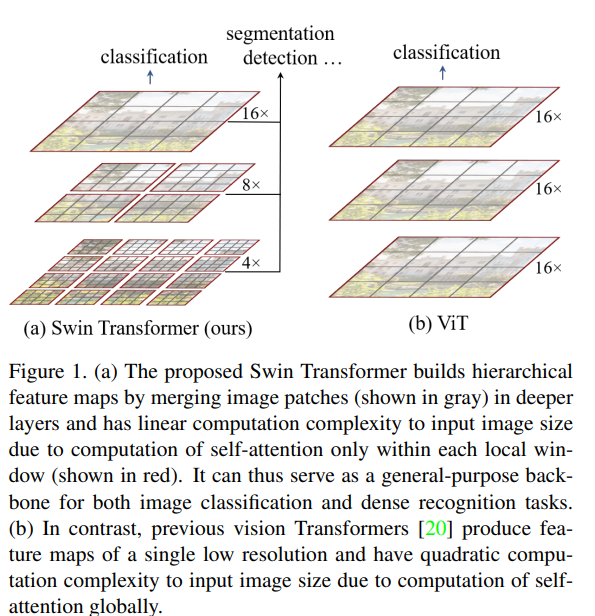
swin transformer旨在构建一个视觉处理领域的通用骨干网络(general-purpose backbone),并且能够应用到各种视觉任务中:包括图像分类,目标检测,语义分割等。将transformer引入视觉任务,面临两大挑战,一个是visual entities的尺度问题(都是自行车,在不同的图片中就不一样),一个是高分辨率的问题,如果以像素点为基本单位的话,根本处理不了这种长度的序列。针对上述问题,作者提出了swim transformer,其中的重点也就两个部分,一个是层级结构(用于捕获不同尺度的特征),一个是shift windows (提高注意力的计算效率)。
我们先来了解下swin transformer的两个核心结构
- 1.Hierarchical Transformer
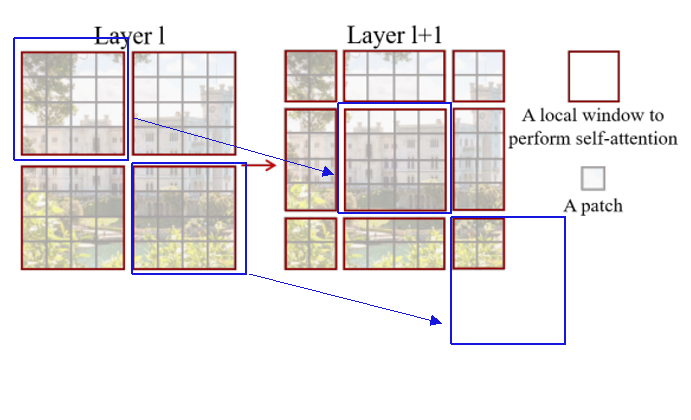
swin transformer从小的patch开始构建不同尺度的特征表示,并且逐渐合并相邻的patch。如何合并patch,后面在讲。
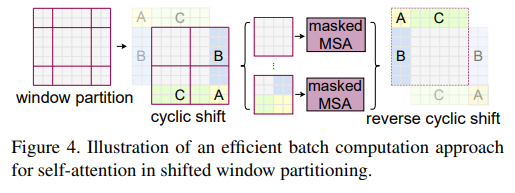
- 2.shift windows
由于swim transformer的注意力都是在window中进行计算,移动窗口时上一层不同窗口中的信息进行了交换,具体如何移动,后面在讲。
现在我们再来看下模型的整体结构,这里以swin-tiny为例,我们会详细的介绍swin transformer核心结构是如何进行计算的
swin transformer的整体结构如下:
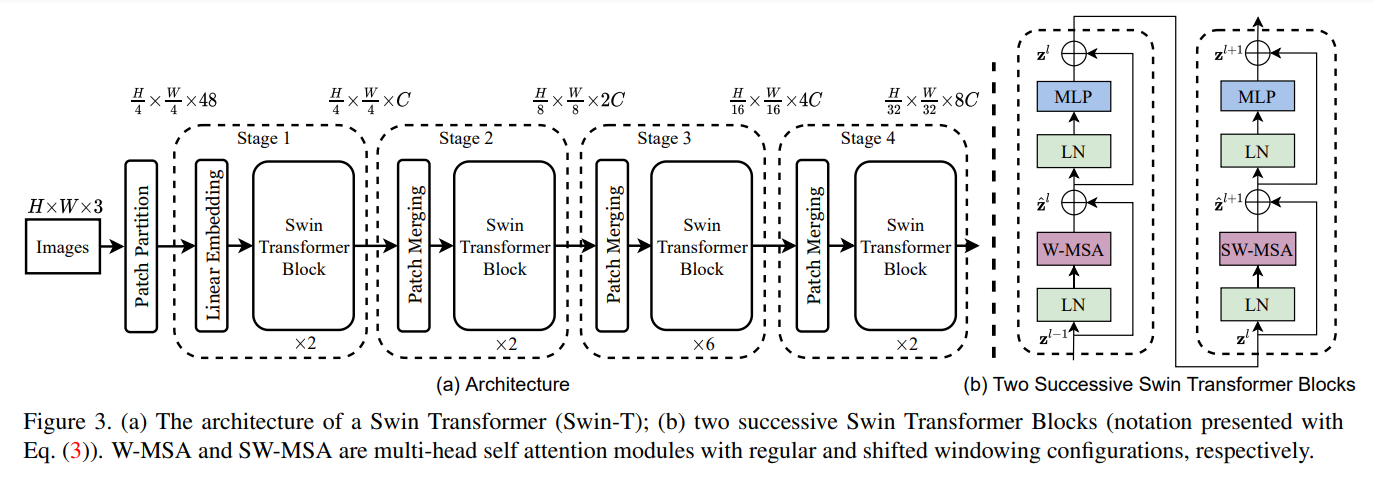
如图,先将RGB图片切割成没有重叠的patch,每个patch看成一个token,每个token的特征是原始RGB像素点的值的拼接。 假设原始图片大小 \(H \times W\times 3\) ,patch size的大小为 \(4\times 4\),经过patch partion过后,图片特征变为\(\frac{H}{4}\times\frac{W}{4} \times(4*4*3)\)。 (以\(224\times 224\times 3\)的图片为例,经过patch partition过后,再将patch平展开,输入特征的shape其实就是\(3136\times 48\))。 后面接上一个线性映射层,将每个patch的维度映射为\(C\)(这里类似NLP中的token embedding),后面利用swin transformer block计算注意力,完成第一阶段的计算。为了能够提出多尺度的特征,在后面的三个阶段,我们通过patch mergeing来减少token的数量,通过transformer block来计算特征。 现在剩下的问题就是
- 1.patch merging 的具体操作流程
在每个stage开始,使用patch merging降采样,缩小分辨率,改变通道数目,具体策略是采样 \(2\times 2\)邻域内的特征
- 2.transformer block是怎么计算的
如上图(b), 每个transformer block分为两个部分,一个部分是W-MSA(window based multi-head self-attention),另一部分是 SW-MSA(shift window based multi-head self-attention),两个模块依次连接。这里面的要点就两个,一个是设置注意力计算的窗口,计算局部特征。第二个使用shift windows 捕获全局特征。其中为提高计算效率,作者采用了cyclic shif的方式,具体可以参考下图。