相关文献可具体参考:Video Action Understanding: A Tutorial
Introduction
视频理解是一个很复杂的任务, 主要围绕对语义方面的识别, 其中包括场景和环境, 实体对象, 动作, 事件, 属性和概念等, 通常视频理解也可称为semantic video understanding。 涉及到具体的任务, 视频理解又包含以下几个方面:
- 1.video classification 视频分类,目前主要任务是给视频中的动作进行分类
- 2.Temporal Action Dection 识别出视频动作中的起始帧和结束帧
- 3.video caption 给视频配上文字说明
- 4.video grounding 给定一句自然语言描述, 定位视频中的具体位置等
Optical Flow
Optical flow or optic flow is the pattern of apparent motion of objects, surfaces, and edges in a visual scene caused by the relative motion between an observer and a scene.Optical flow can also be defined as the distribution of apparent velocities of movement of brightness pattern in an image.(wiki)
光流主要是由于观察者和物体之间的相对运动, 引起视觉场景中的物体, 表面, 边缘表观运动的模式.光流可以用来描述物体的运动.光流技术的主要应用方向在运动估计(motion estimation)和视频压缩(vide compress).在视频领域, 光流常常用在物体检测和跟踪(object detection and tracking), 运动检测(movement detection), 图像主平面抽取(image dominant plane extraction)等.
Paper Reading
整理下视频理解领域的相关文章。从动作识别的具体任务出发,借助这个切入点,梳理下动作识别任务的发展脉络,总结下相关思想和具体思路,完善自己的知识框架。
Two-Stream Convolutional Networks for Action Recognition in Videos(2014)
这篇文章算是视频理解的开山之作,双流网络的模型结构如下:
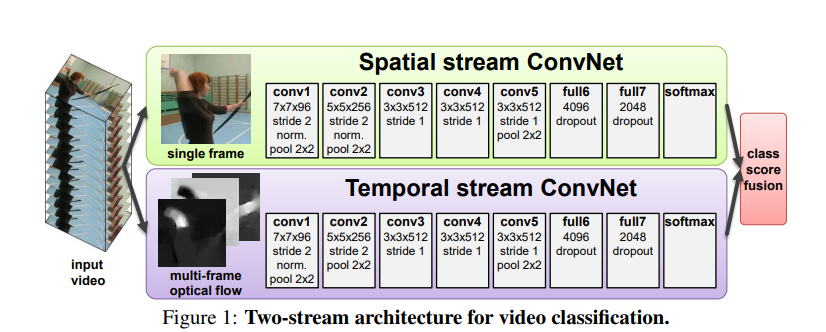
主要包含两个部分:空间流卷积和时序流卷积. 想法其实现在来看比较简单, CNN能够提取2D空间图像特征, 但是感知时序的信息比较差. 既然不能 很好的处理时序信息, 那就把提供抽取好的时序信息喂给模型, 然后融合.
Optical flow ConvNets
光流卷积网络:跟图像卷积网络类似, 由于每两个相邻帧就可以构建一张光流图, 表示成张量就是一个\(w\times h \times 2\)的张量(2表示垂直方向和水平方向的分量).
具体可以参考下图:图(c)就是蓝色区域的光流图特写.

如何利用这些光流特征:文中作者尝试了两种方式optical flow stacking 和trajectory stacking
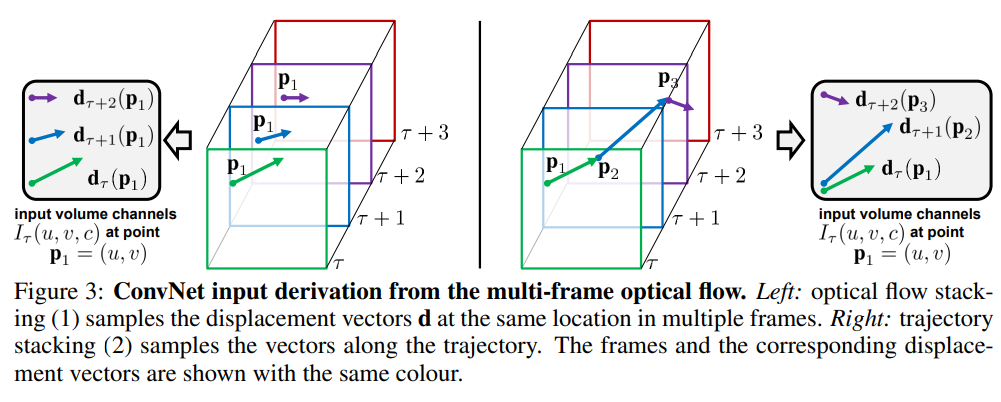
optical flow stacking 对于每个像素点(u, v), 堆叠当前帧的后L个光流图, 构成一个维度为2L的张量, 用来表示当前点的光流 trajectory stacking 利用光流对像素点进行追踪, 先追踪每个像素点的光流, 在进行合并. 具体可以参考上图. 虽然第二种方式用来构建光流网络的输入更有启发性, 但是两种方案的效果性能相当.
早期关于3维卷积网络的研究, 双流网络最致命的缺点就是慢, 抽取光流的算法是非常耗费时间的.
Learning Spatiotemporal Features with 3D Convolutional Networks(C3D 2015)
2D卷积和3D卷积的简单示例:

为什么2D卷积不能很好的提取空间特征:采用多帧视频, L帧看成L个通道, 二维卷积在第一次提取特征过后, 时序信息就已经完全(collapsed completely)坍缩, 后续的卷积操作无法再次感知到时序特征
模型结构非常简单

主要结论:
- 1.3D卷积能够更好的建模形状和运动特征
- 2.使用\(3\times 3\times 3\)的卷积核能够达到最好的效果
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
双流膨胀卷积网络:Two Stream Inflated 3D ConvNet
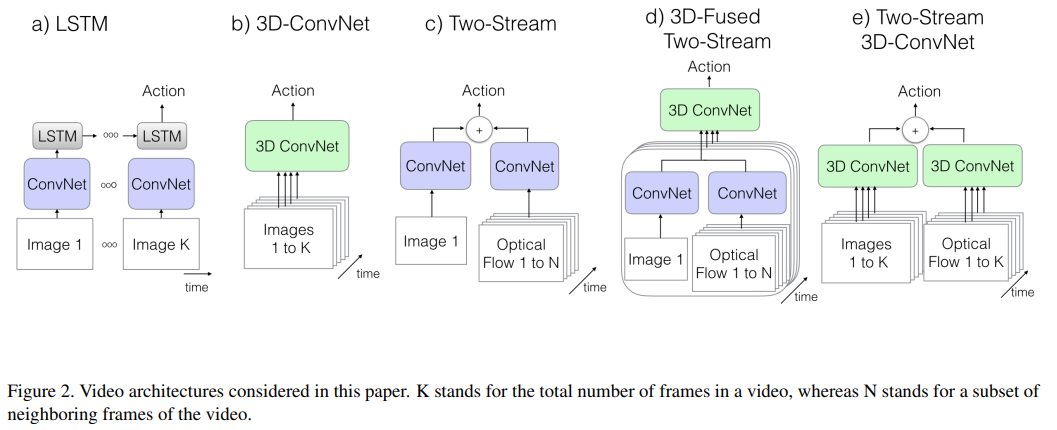
针对现有的特征提取方案之间深入分析和对比:
-
1.ConvNet+Lstm 利用卷积网络提取视频每一帧特征, 再利用lstm构建时序信息
这种方法的优点是可以利用预训练的2D网络权重, 单独抽取每一帧的特征, 缺点也很显然, lstm是基于高维的时序特征进行建模, 缺少低维的特征.
-
2.C3D 直接利用三维卷积网络
三维卷积虽然能够提取时空特征, 但是参数量巨大, 模型训练困难
-
3.Two-Stream Networks 传统的双流网络
参考上图(c)和(d), 两个不同流的特征融合不充分.
-
4.Two-Stream Inflated 3D ConvNets
利用在imagenet上预训练好的模型, 将模型从2D架构改造为3D架构, 将2D的卷积算子和池化算子扩充为3为, 由 \(N\times N\) 膨胀为 \(N\times N\times N\), 那么怎么改造已经做好预训练的模型权重呢?它这里面先将2D的卷积核在时间维度上复制N份, 然后再除以N, 再时间维度上归一化, 保证预训练模型数据分布的一致性. 第二步设置时间维度, 空间维度的步长, 池化窗口等超参. 这里简单说明一下为什么需要调整这些参数, 通常的二维卷积对图像的两个维度(垂直方向和水平方向)是平等对待的, 所以池化的核和步长都是相同的. 现在加入了时间维度, 就应该需要考虑到图像的帧率和图像的分辨率. 如果相对空间而言, 时间增长过快, 会破会混合不同对象的边缘特征, 破坏了早期的特征检测, 如果过慢, 又可能不能很好的获取动态场景.
Is Space-Time Attention All You Need for Video Understanding(2019)
这是一篇将visual transformer应用到视频理解领域的初步尝试。这是一篇实验性文章,作者探索了五种自注意力结构,并提出了一种全新的自注意力机制(divided space-time attention), 该机制在视频分类效果上取得了最优的表现。 这里先说下transformer的优势和迁移到视频领域的主要问题(参考文章):
- 1.卷积网络的归纳偏见(局部连接性和平移不变性),在小数据集上的效果是毫无疑问的,但是在面对足够的训练集会限制模型的表达能力。具体可参考
- 2.卷积核的设计是用来捕获短距离的时空信息,无法建模感受野之外的依赖。通过深度堆叠卷积层,确实能够扩大感受野,但是这种通过聚集短距离信息的方式,仍然有固有的限制。
- 3.训练深层的CNN非常耗费资源。
下面说一下作者对自注意力机制的探索,主要包含五种结构,如下图:
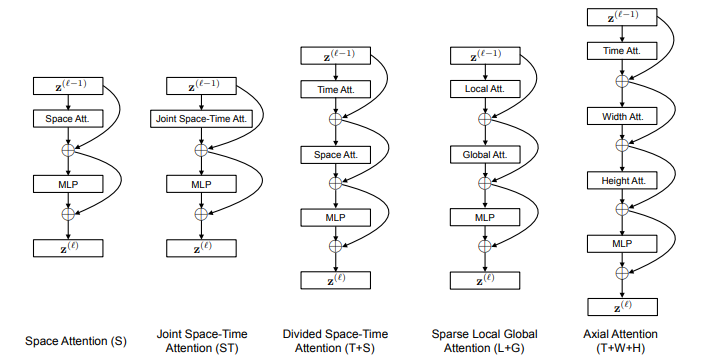
我们根据具体的示例来进行分析:

注意看上面第二张图:其中蓝色的图表示注意力的query block, 其他有颜色的表示在计算自注意力的时候使用到的block, 没有颜色的表示计算自注意力的时候没有用到的block, 相当于是mask。在这里, 视频会按照帧来进行展开成图像的序列,而图像会展开成patch的序列,模型的输入其实就是patch构成的序列。现在我们来一次分析上面的五种自注意力机制。
- 1.空间自注意力机制,每个query(蓝色的patch)只会和当前帧计算自注意力
- 2.联合和空间和时间自注意力机制,每个query不仅和当前帧,还会和其他所有帧计算自注意力。这种方式的问题就是模型消耗显存过大。
- 3.拆分的时间和空间自注意力机制,注意力计算会拆分成两部分,两部分分别计算。空间自注意力,query只跟当前帧计算,时间注意力query只跟每一帧的相同位置的patch进行计算。
- 4.离散的局部全局自注意力机制,对每个query,先计算计算邻域内(\(F\times H/2 \times H/2\))的自注意力(图中的黄色部分),再按照步长为2个patch的方式,计算所有帧离散的全局注意力。(图中的粉红色部分)
- 5.轴注意力机制,分别沿着时间轴,x轴,y轴计算注意力
最后看一下具体的结论
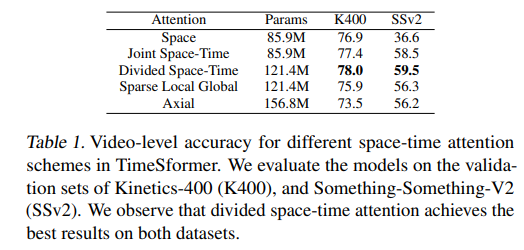
- 1.K400数据集上2D注意力的效果较好,主要原因:K400是一个比较偏重静态图像的视频,放到SSv2效果下降很多
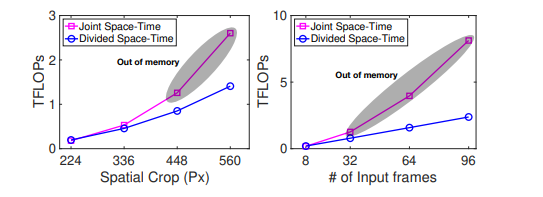
- 2.joint space time注意力机制的参数较小,但是模型占用显存的大小与输入视频帧数和视频裁剪的像素的大小呈现一种指数增长的关系,无法训练较长的视频和分辨率较高的视频
Video Swin Transformer(2021)
swin transformer在图像领域取得了非常好的效果,再各种下游的视觉任务中都达到了sota,很好的验证了transformer结构在图像领域的有效性。在介绍video swin transformer之前,可以先了解下swin transformer。video swin transformer是swin transformer从二维图片到三维视频的自然延申,熟悉swin transformer的很好理解。它强调局部的归纳偏置(inductive bias of locality),能够很好的在训练速度和准确率之间做到很好的平衡。
模型的基本结构如下:
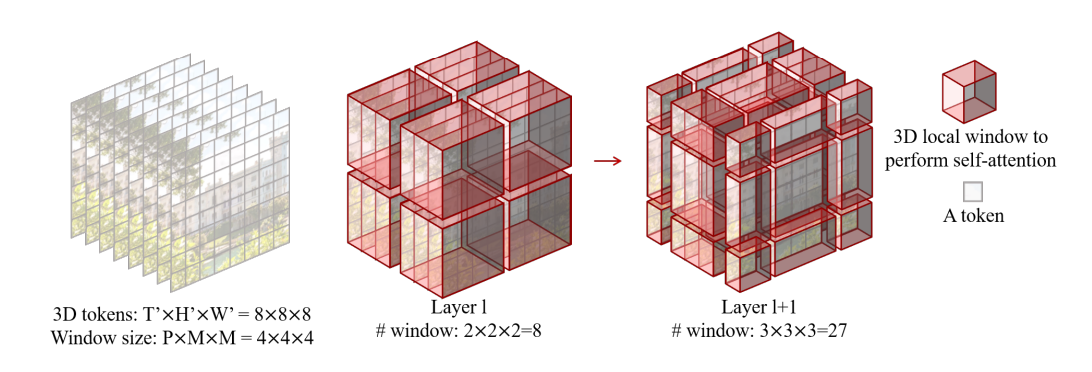
最后我们看下相关结论:
- 在目前公开的动作识别类数据集上(Kinetics-400, Kinetics-600 and Something-Something v2)都达到了目前最好的水平。
- 该模型从swin transformer改变而来,能够利用强大的图像预训练模型来增强video swin transformer的能力。(效果明显,本人实测)